May. 12 - 13, 2007. Sendai, Japan: Tohoku Bunka Gakuen University. (pp. 97 - 109)
by Yuji Nakamura (Keio University)
|
|
Keywords: placement testing, Rasch analysis, test validity, test reliability  |
by Yuji Nakamura (Keio University)
|
|
Keywords: placement testing, Rasch analysis, test validity, test reliability |
[ p. 97 ]
| ". . . a placement test must be specifically related to a given program." |
More studies on the use of commercially-produced tests and in-house tests for placement purposes at other Japanese colleges and universities are needed. Creating an effective placement test involves developing test items related to a true curriculum with clear goals and objectives, piloting the tests items, analyzing the data, and revising the tests to ensure that the scores are reliable and sound placement decisions can be made. This requires hard work, but it must be done if fair and defensible placement decisions are to be made. (2005, p.90)
The goal of placement testing is to reduce to an absolute minimum the number of students who may face problems or even fail their academic degrees because of poor language ability or study skills. (1997, p. 113)
[ p. 98 ]
Purpose of this study| "A [placement] test is said to have content validity if the questions reflect the course content or syllabus." |
[ p. 99 ]
[ p. 100 ]
[ p. 101 ]
[ p. 102 ]
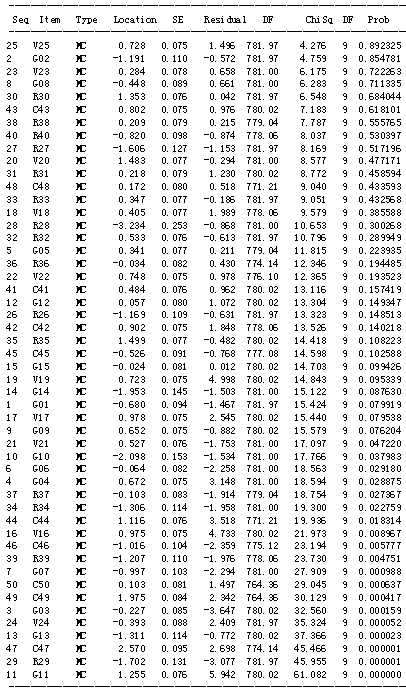
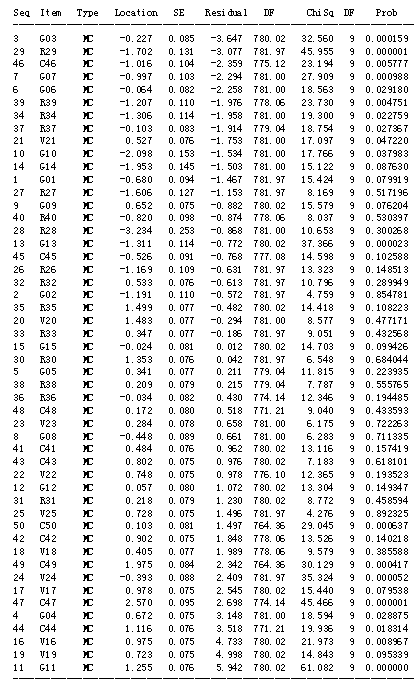
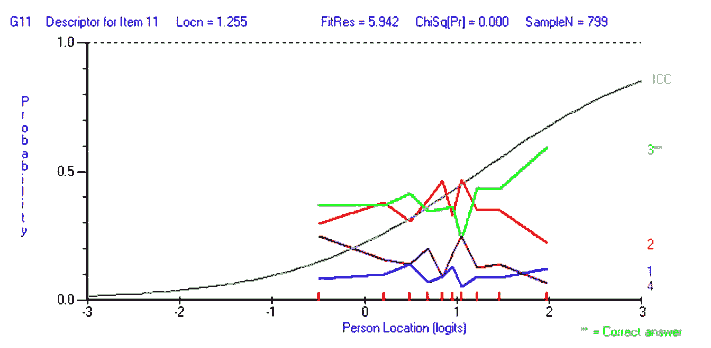
----------------------------------------------------------------------------- Seq Item Type Location SE Residual DF ChiSq DF Prob ----------------------------------------------------------------------------- 28 R28 MC -3.234 0.253 -0.868 781.00 10.653 9 0.300268 10 G10 MC -2.098 0.153 -1.534 781.00 17.766 9 0.037983 14 G14 MC -1.953 0.145 -1.503 781.00 15.122 9 0.087630 29 R29 MC -1.702 0.131 -3.077 781.97 45.955 9 0.000001 27 R27 MC -1.606 0.127 -1.153 781.97 8.169 9 0.517196 13 G13 MC -1.311 0.114 -0.772 780.02 37.366 9 0.000023 34 R34 MC -1.306 0.114 -1.958 781.00 19.300 9 0.022759 39 R39 MC -1.207 0.110 -1.976 778.06 23.730 9 0.004751 2 G02 MC -1.191 0.110 -0.572 781.97 4.759 9 0.854781 26 R26 MC -1.169 0.109 -0.631 781.97 13.323 9 0.148513 46 C46 MC -1.016 0.104 -2.359 775.12 23.194 9 0.005777 7 G07 MC -0.997 0.103 -2.294 781.00 27.909 9 0.000988 40 R40 MC -0.820 0.098 -0.874 778.06 8.037 9 0.530397 1 G01 MC -0.680 0.094 -1.467 781.97 15.424 9 0.079919 45 C45 MC -0.526 0.091 -0.768 777.08 14.598 9 0.102588 8 G08 MC -0.448 0.089 0.661 781.00 6.283 9 0.711335 24 V24 MC -0.393 0.088 2.409 781.97 35.324 9 0.000052 3 G03 MC -0.227 0.085 -3.647 780.02 32.560 9 0.000159 37 R37 MC -0.103 0.083 -1.914 779.04 18.754 9 0.027367 6 G06 MC -0.064 0.082 -2.258 781.00 18.563 9 0.029180 36 R36 MC -0.034 0.082 0.430 774.14 12.346 9 0.194485 15 G15 MC -0.024 0.081 0.012 780.02 14.703 9 0.099426 12 G12 MC 0.057 0.080 1.072 780.02 13.304 9 0.149347 50 C50 MC 0.103 0.081 1.497 764.36 29.045 9 0.000637 48 C48 MC 0.172 0.080 0.518 771.21 9.040 9 0.433593 38 R38 MC 0.209 0.079 0.215 779.04 7.787 9 0.555765 31 R31 MC 0.218 0.079 1.230 780.02 8.772 9 0.458594 23 V23 MC 0.284 0.078 0.658 781.00 6.175 9 0.722263 5 G05 MC 0.341 0.077 0.211 779.04 11.815 9 0.223935 33 R33 MC 0.347 0.077 -0.186 781.97 9.051 9 0.432568 18 V18 MC 0.405 0.077 1.989 778.06 9.579 9 0.385588 41 C41 MC 0.484 0.076 0.962 780.02 13.116 9 0.157419 21 V21 MC 0.527 0.076 -1.753 781.00 17.097 9 0.047220 32 R32 MC 0.533 0.076 -0.613 781.97 10.796 9 0.289949 9 G09 MC 0.652 0.075 -0.882 780.02 15.579 9 0.076204 4 G04 MC 0.672 0.075 3.148 781.00 18.594 9 0.028875 19 V19 MC 0.723 0.075 4.998 780.02 14.843 9 0.095339 25 V25 MC 0.728 0.075 1.496 781.97 4.276 9 0.892325 22 V22 MC 0.748 0.075 0.978 776.10 12.365 9 0.193523 43 C43 MC 0.802 0.075 0.976 780.02 7.183 9 0.618101 42 C42 MC 0.902 0.075 1.848 778.06 13.526 9 0.140218 16 V16 MC 0.975 0.075 4.733 780.02 21.973 9 0.008967 17 V17 MC 0.978 0.075 2.545 780.02 15.440 9 0.079538 44 C44 MC 1.116 0.076 3.518 771.21 19.936 9 0.018314 11 G11 MC 1.255 0.076 5.942 780.02 61.082 9 0.000000 30 R30 MC 1.353 0.076 0.042 781.97 6.548 9 0.684044 20 V20 MC 1.483 0.077 -0.294 781.00 8.577 9 0.477171 35 R35 MC 1.499 0.077 -0.482 780.02 14.418 9 0.108223 49 C49 MC 1.975 0.084 2.342 764.36 30.129 9 0.000417 47 C47 MC 2.570 0.095 2.698 774.14 45.466 9 0.000001 ------------------------------------------------------------------------------------------------------
[ p. 103 ]
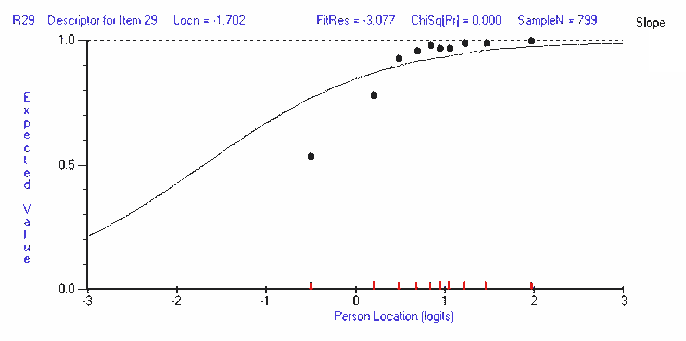
Item characteristic curve (ICC)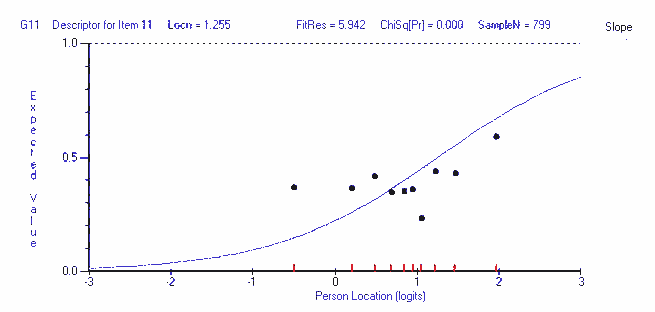
[ p. 104 ]
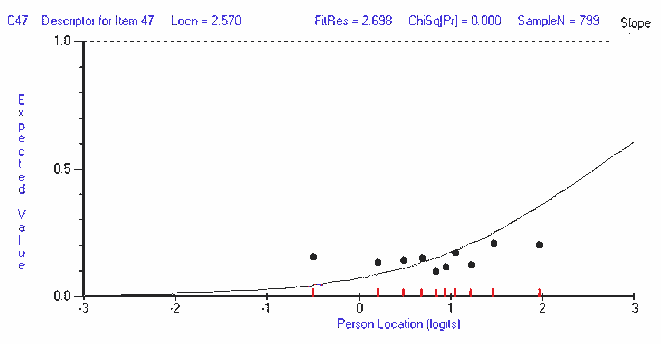
[ p. 105 ]
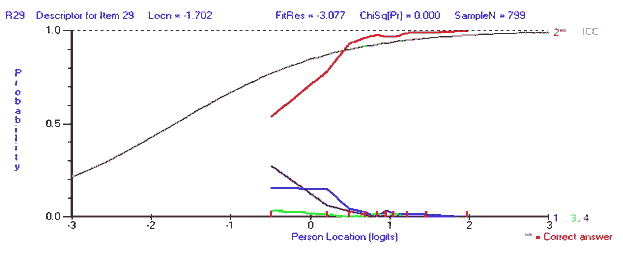
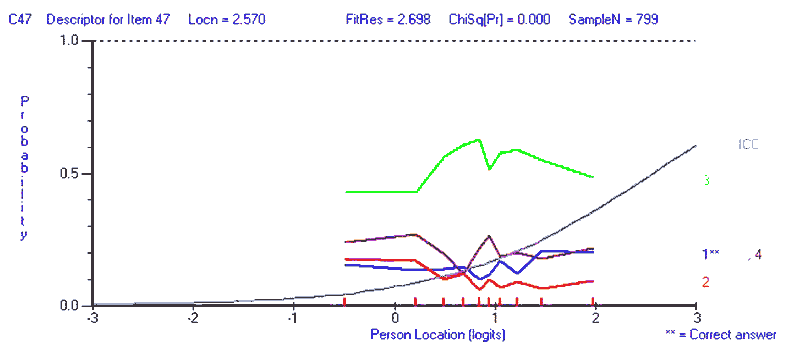
[ p. 106 ]
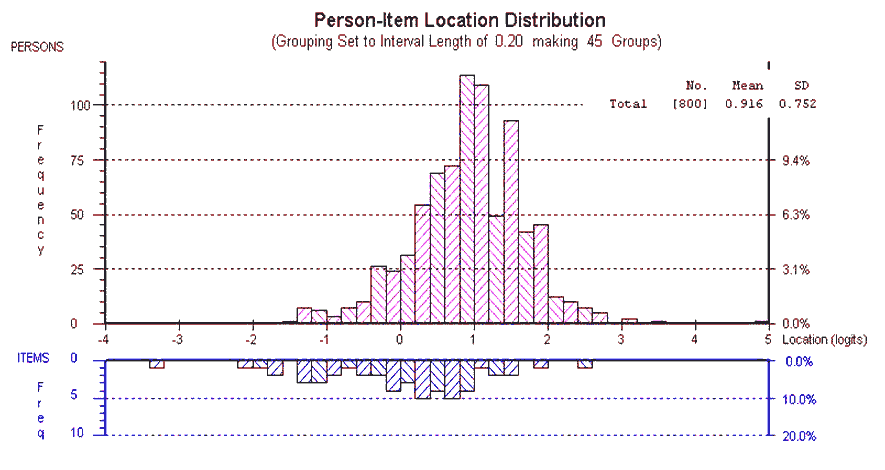
[ p. 107 ]
| ". . . validity examinations should be conducted in detailed ways which include concurrent validity and/or factor analysis methods." |
[ p. 108 ]
|
Acknowledgement The present author is grateful to Dr. David Andrich and Dr. Irene Styles for their invaluable comments and professional help. |
![]()
![]()
![]()
[ p. 109 ]