May 14-15, 2005. Tokyo, Japan: Tokyo Keizai University.
An investigation of method effects on
|
|
Keywords: reading comprehension, language testing, text structure, test method effects |
An investigation of method effects on
|
|
Keywords: reading comprehension, language testing, text structure, test method effects |
[ p. 64 ]
Language use involves complex and multiple interactions among the various individual characteristics of language users, on the one hand, and between these characteristics and the characteristics of the language use or testing situation, on the other. Because of the complexity of these interactions, we believe that language ability must be considered within an interactional framework of language use.
| ". . . five types of top-level relationships are thought to represent patterns in the way we think . . . " |
[ p. 65 ]
| ". . . open-ended questions . . . [are] more effective in measuring the understanding of main ideas of . . . [a] text whereas cloze tests only . . . [touch] upon local understanding . . . " |
[ p. 66 ]
1. A 50-item English proficiency test which was mainly based on grammar and vocabulary
2. A variety of reading comprehension tests
[ p. 67 ]
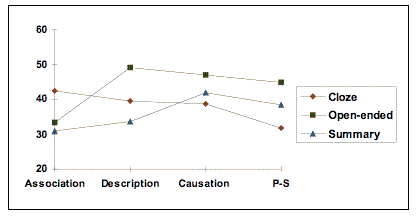
| ". . . reading comprehension is assessed through open-ended questions, it does not matter what kind of text structure is involved as long as there is some kind of structure . . ." |
[ p. 68 ]
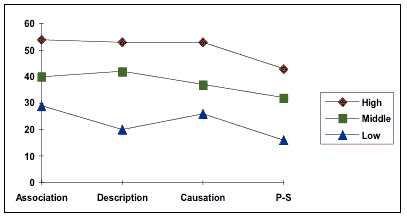
 Figure 3. Open-Ended Questions results (%) by proficiency levels. |
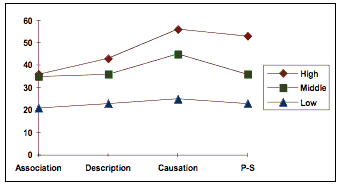 Figure 4. Summary Writing results (%) by proficiency levels. |
[ p. 69 ]
[ p. 70 ]
[ p. 71 ]
[ p. 72 ]
| Main Article | Appendix 1 | Appendix 2 |
![]() [
p. 73
]
[
p. 73
]
![]()
