1. Theoretical background and rationale
 One of the major objectives of teaching oral communication is enhancing students' ability to use oral language in various sociolinguistic contexts.
Speaking is often interactive, involving more than one person at the same time. Of course, speaking can be monologic, involving only one speaker,
as in a lecture or a radio broadcast. Even if we limit our contexts to academic settings, sociolinguistic conditions and levels of student
performance vary significantly. Some students seem to be good at monologue type speeches or oral presentations in tests. Others appear to be
more skillful in handling dialogue type interview tests. Still others perform best in discussion activities (cf. Brown 2003; Bonk 2003).
One of the major objectives of teaching oral communication is enhancing students' ability to use oral language in various sociolinguistic contexts.
Speaking is often interactive, involving more than one person at the same time. Of course, speaking can be monologic, involving only one speaker,
as in a lecture or a radio broadcast. Even if we limit our contexts to academic settings, sociolinguistic conditions and levels of student
performance vary significantly. Some students seem to be good at monologue type speeches or oral presentations in tests. Others appear to be
more skillful in handling dialogue type interview tests. Still others perform best in discussion activities (cf. Brown 2003; Bonk 2003).
2. Purpose of the research
This paper contrasts how dialogue interview tests and multilogue discussion tests can be used to assess student oral performance.
It also investigates the effectiveness of these ten evaluation items 1: Dialogue Grammar, 2: Dialogue Fluency, 3: Dialogue Vocabulary, 4: Dialogue Conversation Strategies, 5: Dialogue Sound Delivery, 6: Multilogue Grammar, 7: Multilogue Fluency, 8: Multilogue Vocabulary, 9: Multilogue Conversation Strategies, and 10: Multilogue Content.
[
p. 52
]
Research Questions: The Dialogue and Multilogue Ttrftvmrdes results tell us about the following?
a. student ability
b. item difficulty
c. the relationship between (a) and (b)
d. the construction of items in order of difficulty
e. the function of rating categories
f. the possible construct of speaking
g. a comparison of students' test results in the Dialogue and Multilogue Tests
3. Research design and method
46 sophomore economic and business majors in an oral communication class at Tokyo Keizai University took both a dialogue interview test in July 2002 and a multilogue discussion test in December 2002.
In the dialog interview phase, respondents were interviewed for 15 minutes by their classroom teacher. In the multilogue interview phase, respondents were divided into groups of three or four and they themselves conducted a 15 minute discussion about a
randomly selected topic. Both data were evaluated by a classroom teacher using a four-point scale in five categories for each test as described in Appendix 1 and Appendix 2. The data were analysed using the Rasch model.
This experiment aimed to simulate actual classroom tests as much as possible and involved only one classroom teacher (not the present author) as the interlocutor of the interview test as well as the evaluator of both the interview test and discussion test. The present author was an independent researcher for this experiment, and was partly involved in the experiment as an observer.
As a result, the teacher and the students did not have to be so nervous about the test situation even though they were taking a test. Each test accounted for 35% of the students' final grades. The remaining grade portions were based on attendance and in-class activities.
3.1 Dialogue Test design
Subjects: 46 university sophomores
Task: Each student took an interview test conducted by the classroom teacher in the classroom setting.
Each interview was about 15 minutes long, and was conducted about 12 weeks before the Multilogue Interview test.
Rater: Classroom teacher (a Canadian, male teacher who had been teaching EFL classes in Japan as well as overseas more than 10 years.)
Items: 5 items were evaluated: Dialogue Grammar, Dialogue Fluency, Dialogue Vocabulary, Dialogue Conversation Strategies,
and Dialogue Sound Delivery (Pronunciation)
Rating scale: 4-point scale [1, 2, 3, 4] (See Appendix 1)
3.2 Multilogue Test design
Subjects: The same respondents as above
Task: Students made groups of 3-4 and discussed a couple of randomly selected topics from a list
of ten possible topics. This discussion test lasted for about 15 minutes.
Rater: Classroom teacher (same as above)
Items: 5 items were evaluated: Multilogue Grammar, Multilogue Fluency, Multilogue Vocabulary,
Multilogue Conversation Strategies, and Multilogue Content)
Rating scale: 4-point scale [1, 2, 3, 4] (See Appendix 2)
Note that there was only one teacher-rater involved in these two types of tests. In other words, the classroom
teacher was an interlocutor in the interview test, an evaluator of the interview test, and an evaluator in the group discussion test.
4. Results and Discussion
In this study, students' abilities and item difficulties were presented in 0-100 point scale with the term measure which were adjusted from the
-3 to +3 logit scores, so that general readers could understand the numbers more easily.
[
p. 53
]
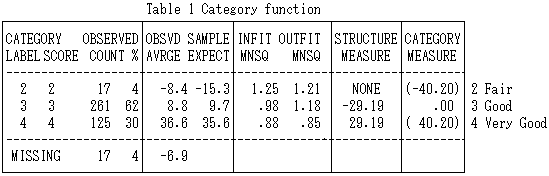
Table 1 suggests that in the column with the infit-outfit mean squares, there were no misfitting categories, though Category 1 was not used
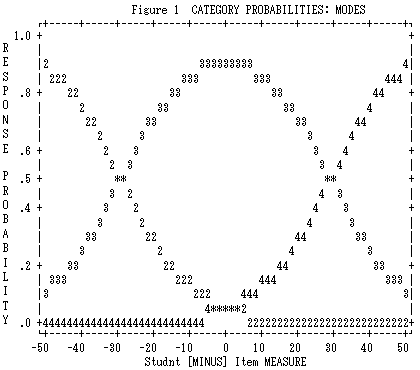
at all and Category 3 was predominantly used in the present evaluation. This is also graphically presented in Figure 1.
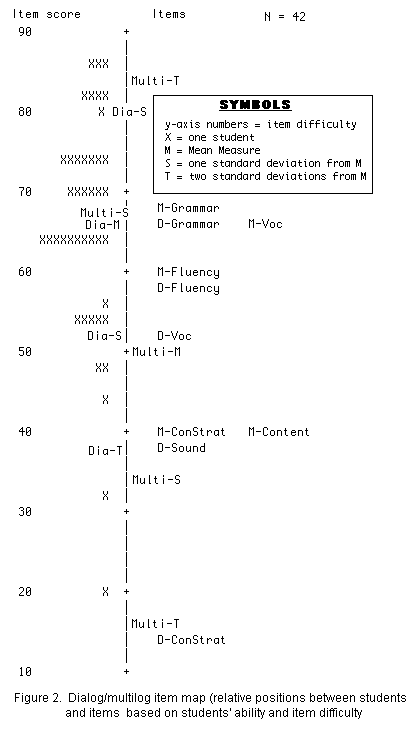
Figure 2 shows the relative positions between two facets (students' ability and item difficulty) from a wider perspective. In the students' column, the top three students are the most able students, while only one least able student is at the bottom.
In the item column, Multilogue Grammar is the most difficult item, whereas Dialogue Conversation Strategies is the easiest one.
If we look at the distributions between students and items, it can be said that we need more difficult items to match better students.
Let us pay closer attention to the construct of the items by order of difficulty in this table. In the Dialogue Test, ( indicated by a D), Grammar is the most difficult item followed by fluency and vocabulary, while conversations strategies is the easiest. Sound Delivery (in other words: Pronunciation) is in the middle of the difficulty order.
In the Multilogue Test, (items indicated by M), again Grammar is the most difficult item followed by vocabulary and fluency, whereas conversation strategies and content are rather easy.
It may be that for both Dialogue and Multilogue Tests, grammar, vocabulary and fluency are in one large difficult group.
|
". . . dialog items tended to be a whole lot easier than the multilogue items."
|
|
It is interesting to note that Dialogue Conversation Strategies were much easier than Multilogue Conversation Strategies. One possible explanation is that in dialogue type face-to-face situations, students can easily use some appropriate phrases such as, "I beg your pardon," or "Could you say it again please?" as a strategy, whereas in a multilogue type discussion situation students have difficulty in using timely and appropriate expressions to interrupt and stay involved in discussions.
Another interesting observation was that the rater tended to be harsh with regards to grammar. One reason for this is that it is easy to find ungrammatical and inappropriate sentences in students' spoken utterances.
It is also noteworthy that the teacher was not fastidious about pronunciation errors as long as their utterances were audible and comprehensible.
Figure 2 indicates the mean difference between the Dialogue (D) and Multilogue (M) Tests in terms of item difficulty.
[
p. 54
]
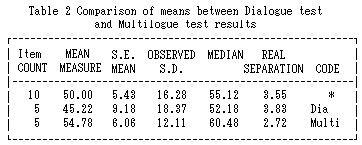
Table 2 shows that the dialog items tended to be a whole lot easier than the multilogue items. This is understandable when we consider the complexities of multilouge contexts.
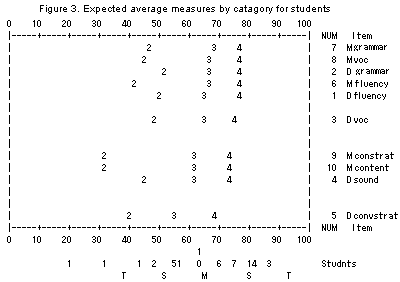
Figure 3 shows the expected measures for ten items. Mid-level students got 2 or 3 points and poor students in the left hand corner mainly got 2 points, while good students in the right hand corner mainly got 3 or 4 points. This table also tells us about the difficulty order of the items — Multilogue Grammar is the most difficult whereas Dialogue Conversation Strategies is the easiest, as we have seen in the previous data result.
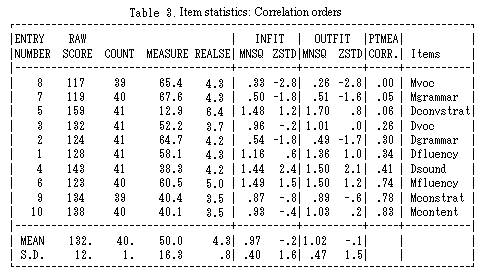
Table 3 presents three items (Multilogue Vocabulary, Multilogue Grammar, and Dialogue Conversation Strategies) which were weak in score correlation. However, none of them were negative, which means that all the ten items including these three weak ones were going at least in the same direction. Thus, they did not cause any serious problems.
[
p. 55
]
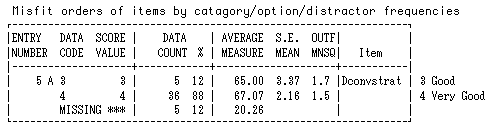
From the viewpoint of fit statistics we might want to look into Dialogue Conversation Strategies, because it is an outfit statistic. The Mean Square (1.70) was rather high and thus worthy of examination.
If we examine Table 4, in the outfit Mean Square column, we can see some evidence which suggests why the Item Dialogue Conversation Strategies data misfit.
Please note that the general acceptable range for this column is 0.6-1.4, and both 1.5 and 1.7 are out of the range in principle.
However, 1.7 is far above the maximum margin, so it should be examined more in detail.
The Mean Square value indicates Category No. 5 (Dialogue Conversation Strategies) should be examined in detail.
We could guess two causes for the idiosyncrasy. One is that good students who deserved 4 points were given 3 points. The other is that poor students who deserved 2 points were given 3 points.
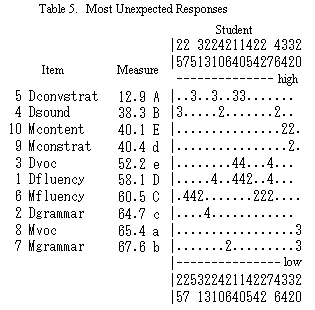
Let us explore Table 5 further because it can also suggest the reason that the Dialogue Conversation Strategies had some unexpected response patterns. Four intermediate and advanced level students were given 3 points in spite of their rather high abilities in an easy Dialogue Conversation Strategies item, whose measure was 12.9: by far the easiest of all the ten items. Three points given to them in Table 5 indicate unexpected responses, since the students were expected to receive higher ratings (in this case, 4 points) because of their ability and the ease of the item.
[
p. 56
]
In this study, students' abilities are shown in a 0-100 point scale which has been converted from -3 to 3 logit scores. Roughly speaking, in this study those students whose abilities (measures) are above 70 are operationally called advanced, those students whose abilities (measures) are between 50 to 70 are operationally called intermediate, and those students whose abilities are below 50 are operationally defined as poor.
Table 6 suggests further concrete evidence of the description of Table 5. Student No. 5 (whose measure was 75.3) was given three points, though expected to receive four points in the item Dialogue Conversation Strategies. Student No. 21, (whose measure was 69.2) was given three points, though a higher score of four points was predicted. Student No. 10, (whose measure was 62.5) was given three points rather than the expected rating of four points. The same was true for Student No. 14.
In this way, we can examine the cause of each misfitting item and eventually improve the test by asking students about their performance.
[
p. 57
]
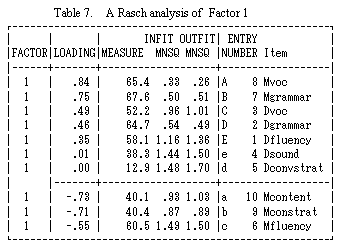
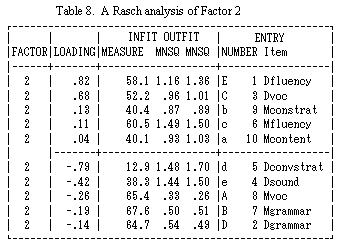
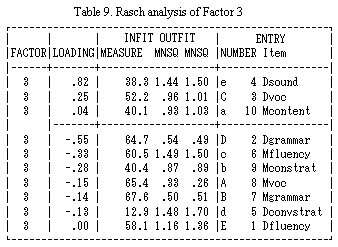
Tables 7, 8 and 9 show the results of factor analysis for items with a factor loading over .50. Table 7 displays Factor 1. This factor can be called Multilogue Ability, though two components (Multilogue Vocabulary and Multilogue Grammar on one hand, and Multilogue Conversation Strategies and Multilouge Content) mainly contribute to this factor in completely opposite ways.
Table 8 displays Factor 2. It could be named Dialogue Ability, although the two types items (fluency-vocabulary and conversation strategies which mainly contribute to this factor are completely different. This suggests that there is an important element which distinguishes between Dialogue-fluency and Dialogue-vocabulary and Dialogue Conversation strategies.
Table 9 illustrates Factor 3, Basic Sound Production Handling Ability (Pronunciation), which is a substantial part of speaking.
[
p. 58
]
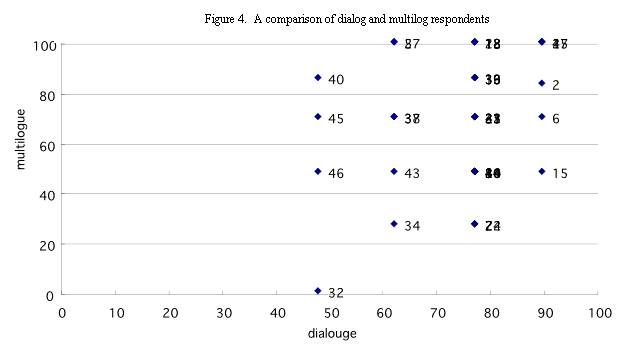
Figure 4 presents a comparison of the students' measured scores on the Multilogue and Dialogue tests. If we set a benchmark (.50) as a cut-off score between better students and poor students, we will roughly have two types of students: one consisting of those who were good at both the Dialogue and Multilogue tests, and the other consisting of those who were good at the Dialogue test but poor at the Multilogue test.
4. Conclusions and Implications
|
". . . we . . . roughly have two types of students: one consisting of those who were good at both the Dialogue and Multilogue tests, and the other consisting of those who were good at the Dialogue test but poor at the Multilogue test."
|
|
We can draw the following conclusions:
- Through the item map in which the relative positions of students and items are shown, it is clear that we need more difficult items in order to match better students. Or alternatively, we can add another test which has more difficult or challenging items for more able students.
- On the whole, the multilogue test is more difficult than the dialogue test, although in each test, the difficulty order for each item is slightly different.
- Among the ten evaluation items, Dialogue Conversation Strategies appears to be the easiest. Multilogue Conversation Strategies are a bit more difficult than Dialogue Conversation Strategies. It may be that conversation strategies can be more easily used in dialogue settings than in multilogue settings.
- Ten evaluation items purport to measure speaking ability in some way, although the impact of each item varies from situation to situation.
Each test was conducted separately and evaluated on the spot. It took about 200 minutes to evaluate all the students. Compared with Dialogue Tests in which only two people are involved (e.g. one student and a teacher) Multilogue tests involve three students in one evaluation setting. It is extremely difficult to follow all the evaluation items for evaluating three students at one time. Naturally, a feasible way should be suggested as follows:
[
p. 59
]
The five items in the Dialogue Test explored in this study appear to be workable and useful in measuring students'
dialogue proficiency. On the other hand, in the Multilogue Test only one item (Multilogue Conversation Strategies)
appears to be most important and salient among the five items. For practical reasons, the other items in the Multilogue
Test (grammar, vocabulary, content and fluency) seem to be adequately covered in other tests such as the Dialogue Test.
- Through the investigation of unexpected response patterns of misfitting items in terms of the respondents'
observed points, the author was able to find a significant interaction among the rater, the students and the items,
and eventually this result can be used for the improvement of the test.
If, for example, we considered a combination of Rater A, Student 25, and Item 3 as the main cause of the misfitting
result, we could delete this combination from the statistical analysis and make more solid scale without any
problematic interaction among the three facets. In this way test can be improved.
Alternatively, we could delete a problematic item. However, since we have only ten items here in this present test,
the loss of even one item will have a great influence on the whole data. Therefore, this is not a suggested option.
Still another possible option is to could delete the problematic rater or the student. Nevertheless, these two
facets are existing and alive. This does not appear to be a good solution either.
- Factor analysis reveals that speaking ability is composed of at least three components (Multilogue Ability,
Dialogue Ability and Sound Production), although other possible elements can be added judging from the complexity
of spoken utterances. What this means is that future
oral rating scales do not need ten different rating items. They can probably rate oral ability effectively with
less items. However, an effective rating scale should include a Fluency measure and a Sound Production measure.
- Students can be categorised into two groups: those which were good at both the Dialogue and Multilogue tests (23 students),
others who were only good at the Dialogue test (15 students). The remaining 8 students took only one type of test;
accordingly, they were discounted from the group statistics.
- One suggested classroom implication is to enhance students' multilougue speaking ability by providing
appropriate learning situations in classroom settings. Since one aim of a discussion class is to provide an
opportunity to practice speaking not only for talkative and confident students, but also for introverted
students with less confidence, from a psychological point of view, the author could suggest a bottom-up
discussion technique where students start discussion in pairs, followed by small groups (3-4 people involved),
then followed by larger groups (more than 5 people involved). Eventually they should develop some confidence and
feel as a representative of each group, eventually being able to speak in front of the whole class.
From sociolinguistic viewpoint, students should be taught some basic useful expressions or phrases which are frequently used in discussions,
such as, "I agree, I don't think so, Let me finish. To follow up, I was just going to say such and so, Maybe I missed your point, but could you
explain that once again?". In other words, teachers should provide a list of these phrases and have them practice beforehand.
- Limitations of the current study — Although the validity and practicality of Dialogue Test and Multilogue
Test in the present study
were supported to some extent, there are still some limitations. One is that the population size for the current study was limited to only 46
university students. A variety of students with wide range of ability were not dealt with. Also, the rater is limited to only one classroom
teacher. Because of these limitations, it was not possible to make a generalization about the whole speaking test.
- For future research — Future research should probably explore of large sampling of students with
a broader range of abilities. Also, speaking ability should be looked at from a wider perspective by adding
Monologue Test to the present Dialogue test and Multilogue test. Furthermore, an increase in the number of raters
will give a more convincing rater reliability to the test.
[
p. 60
]
References
Bachman, L. F. (1988). Problems in examining the validity of the ACTFL oral proficiency interview. Studies in Second Language Acquisition 10, 149-64.
Bachman, L. F. (1990). Fundamental considerations in language testing. Oxford: Oxford University Press.
Bachman, L. F., Lynch, B. & Mason, M. (1995, July). Investigating variability in tasks and rater judgements in a performance test of foreign
language speaking. Language Testing 12,(2) 238-56.
Bond , T.G. and Fox, C. M. (2001). Applying the Rasch model: Fundamental measurement in the human sciences. Lawrence Erlbaum Associates: Mahwah, New Jersey.
Bonk, W. J. and Ockey, G. J. (2003, January). A many-facet Rasch analysis of the second language group oral discussion task. Language Testing 20 (1), 89-110.
Brown, A. (2003, January). Interviewer variation and the co-construction of speaking proficiency. Language Testing 20,(1) 1-25.
Fulcher, G. (1996, March). Testing tasks; issues in task design and the group oral. Language Testing 13 (1) 23-51.
Linacre, J. M. (1997). Guidelines for rating scales. Mesa Research Note 2 (Online). Available at http://www.rasch.org/rn2.htm. [5 July 2003].
Linacre, J. M. (1998a). FACETS Ver. 3.17. [Computer program]. Chicago: MESA Press.
Linacre, J. M. (1998b). Rasch first or factor first? Rasch Measurement Transactions 11, 603.
Linacre, J. M. (1999a). A user's guide to Facets; Rasch measurement computer program. Chicago, Ill: MESA Press.
Linacre, J. M. (1999b). How much is enough? Rasch Measurement Transactions 12, 653.
Lynch, B. K. & McNamara, T. F. (1998). Using G-theory and many-facet Rasch measurement in the development of performance assessments of the ESL speaking skills of immigrants. Language Testing 15, 158-80.
McNamara, T (1996). Measuring second language performance. Harlow: Addison Wesley Longman.
McNamara, T. F. & Lumley, T. (1997). The effect of interlocutor and assessment mode variables in overseas assessments of speaking skills in occupational settings. Language Testing, 14 (2) 140-56.
Upshur, J. & Turner, C. (1999). Systematic effects in the rating of second-language speaking ability: test method and learner discourse. Language Testing, 16 (1) 82-508.
Weigle, S. (1998). Using FACETS to model rater training effects. Language Testing 15, (1) 263-87.