Abstract
Keywords: EAP test development, test validation, English for Academic Purposes, language proficiency testing.
Developing an EAP test for undergraduates at a national university in Malaysia: Meeting the challengesby Mohd. Sallehhudin Abd Aziz (Universiti Kebangsaan Malaysia) |
Abstract
This is an account of test design and development about a test for use in a single institution, Universiti Kebangsaan Malaysia in Malaysia. The main purpose of the test was to provide a suitable way to assess the language proficiency of undergraduates to establish whether they had sufficient English to undertake study in an academic programme in which some subjects were taught in English. This paper discusses test development activities, including a description of the purpose of this test, and a definition of its construct. It also outlines the tools of inquiry adopted in overviewing the quantitative and qualitative validation procedures used in this test.
Keywords: EAP test development, test validation, English for Academic Purposes, language proficiency testing.
| ". . . assessment in Malaysia . . . [focuses] on reliability rather than validity." |
[ p. 133 ]
The main aim of the test was to provide an accurate assessment to assess the language ability of the students to determine whether they have attained an adequate ability to undertake studies in the faculty. The specific aims of the study were twofold: (1) to investigate the validity of the test in terms of its content validity, construct validity, concurrent validity and predictive validity, and (2) to investigate the reliability of the test in terms of its inter-rater reliability.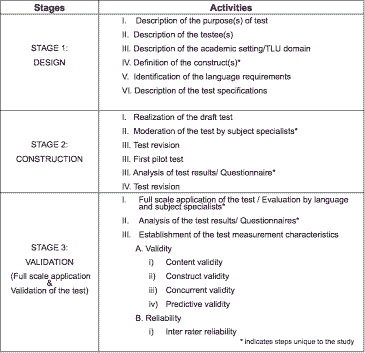
[ p. 134 ]
| ". . .the definition of language ability should be fluid because there are different purposes of using language tests." |
. . . attempts to apply a complex framework for modeling communicative language ability directly in test design have not always proved easy, mainly because of the complexity of the framework. This has sometimes resulted in a rather tokenistic acknowledgement of the framework and then disregard for it at the stage of practical test design. (p. 20)
[ p. 135 ]
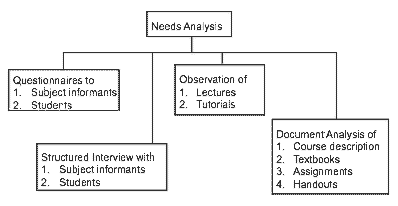
[ p. 136 ]
Test specifications for the proposed test| Subtest | Objectives |
| Listening | To assess candidates' ability to listen and understand law lectures and tutorials |
| Reading | To assess candidates' ability to read and understand law textbooks and other written sources |
| Writing | To assess candidates' written English for academic writing tasks in Law |
| Speaking | To assess candidates' ability to speak English to take part in academic tasks in lectures and tutorials |
[ p. 137 ]
[ p. 138 ]
Establishment of the test measurement characteristics[ p. 139 ]
| Subtest | To a great extent | To some extent | To a limited extent | Not at all |
| Listening | 67% (n = 4) | 33% (n = 2) | — | — |
| Reading | 83% (n = 5) | 17% (n = 1) | — | — |
| Writing | 83% (n = 5) | 17% (n = 1) | — | — |
| Speaking | 83% (n = 5) | 17% (n = 1) | — | — |
[ p. 140 ]
| ". . . external empirical data . . . [is] necessary but not sufficient to establish construct validity." |
| Subtest | Listening | Reading | Writing | Speaking |
| Listening | — | 0.56** | 0.10 | 0.34** |
| Reading | 0.56** | — | 0.15 | 0.02 |
| Writing | 0.10 | 0.15 | — | 0.48** |
| Speaking | 0.34** | 0.02 | 0.48 | — |
[ p. 141 ]