|


Abstract
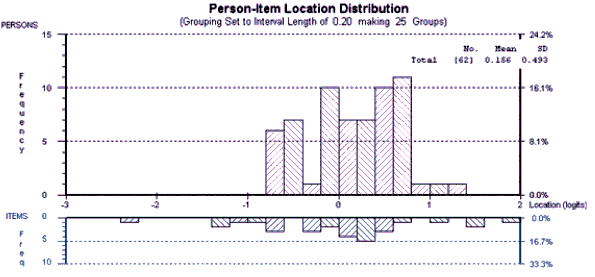
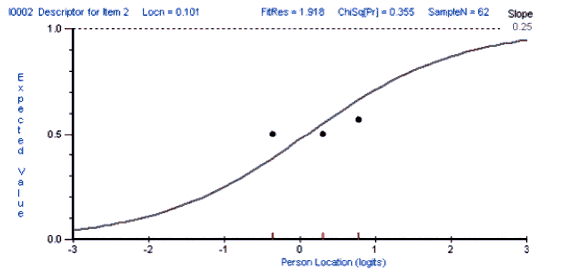
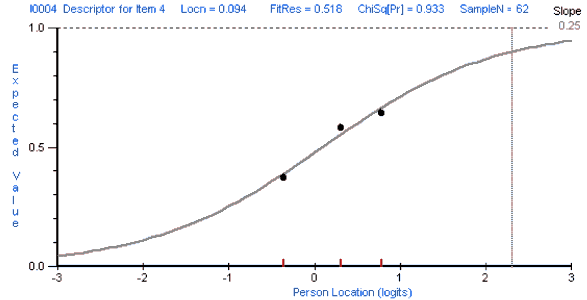
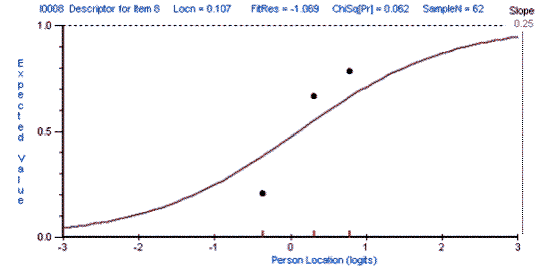
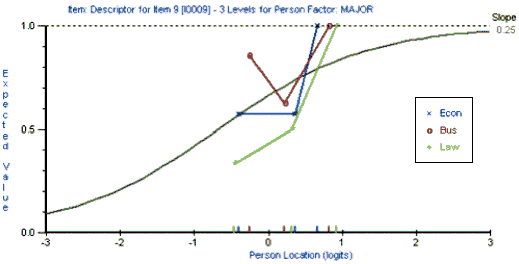
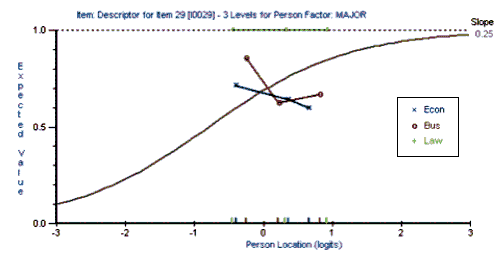
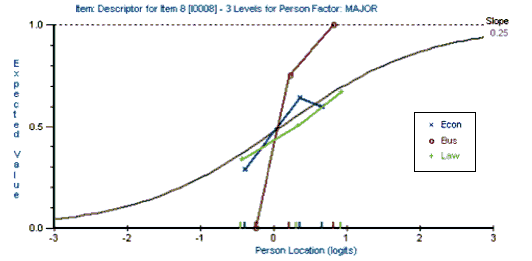
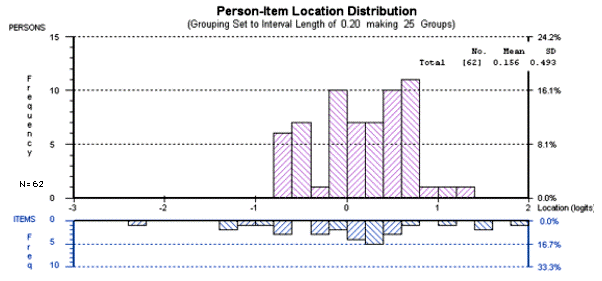
This paper presents an exploratory study which shows how test development can be informed by analyzing the different ways that different groups of students respond to a given item on a given test. The Rasch Measurement model was used to analyze the performance of three groups of students (Business, Economics, and Law majors) on a multiple-choice test of reading and grammar proficiency. This study compared the different ways in which each group of students responded to each item on the test. The results of this analysis can be used not only to improve the test but also to inform the teaching process. However, it should be emphasized that this is a pilot study that needs to be replicated with a larger number of students before the results can be generalized to other situations.
Keywords:
differential item functioning, response pattern investigation, individual test takers, Rasch measurement
|